此帖使用 docker compose 来 Grafana 和 Prometheus 环境。为什么用 docker compose 来部署,因为使用 1 个 docker-compose.yml 文件就可以配置应用程序的所有服务,可移植性高,单个主机上可形成多个隔离环境防止不同服务和项目互相干扰等等
只是进行简单入门安装部署 Grafana 和 Prometheus,帮助大家实现 1 个高级探针的梦想。网上教程很多,此帖内容可以仅作为参考。后续更多更难的个性化配置不写,因为实在是太多了,有兴趣可以直接看官网 doc
这帖子是我随便写写的,没有认真去排版什么的,有错误或不详之处尽量提出
安装docker和docker-compose
看看官网安装就行,不复杂。或者用其他的脚本安装 docker, docker engine, docker compose 也行
Install Docker Engine | Docker Documentation
Install Docker Engine on Debian | Docker Documentation
Install Docker Engine on Ubuntu | Docker Documentation
目录结构
docker-compose.yml 目录下的当前结构参考,.env 是环境变量文件,grafana.ini 是 grafana 的配置文件
grafana.ini 原始文件在 GitHub 上有:grafana/conf/sample.ini at main · grafana/grafana
prometheus.yml 同理:prometheus/documentation/examples/prometheus.yml at main · prometheus/prometheus
.
├── docker-compose.yml
├── .env
├── grafana
│ ├── conf
│ │ └── grafana.ini
│ └── provisioning
│ ├── dashboards
│ └── datasources
│ └── datasource.yml
└── prometheus
└── prometheus.yml
我的是这样
.
├── alertmanager
│ └── config
│ └── alertmanager.yml
├── docker-compose.yml
├── flush
├── grafana
│ ├── conf
│ │ └── grafana.ini
│ └── provisioning
│ ├── dashboards
│ │ ├── default.yaml
│ │ └── node_exporter_full.json
│ └── datasources
│ └── datasource.yml
├── loki
├── mosquitto
│ └── mosquitto.conf
└── prometheus
├── node.json
├── prometheus.yml
├── rules
│ └── alert_rule.yml
└── web.yml
docker compose及环境变量配置
基础 docker-compose.yml 配置差不多就这样写,可根据自己需要减少或增加 service
volumes:
prometheus_data: {}
grafana_data: {}
networks:
monitoring:
services:
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- "--path.procfs=/host/proc"
- "--path.rootfs=/rootfs"
- "--path.sysfs=/host/sys"
- "--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)"
ports:
- "9100:9100"
networks:
- monitoring
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: unless-stopped
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--web.console.libraries=/etc/prometheus/console_libraries"
- "--web.console.templates=/etc/prometheus/consoles"
- "--web.enable-lifecycle"
- "--web.enable-admin-api"
ports:
- "9090:9090"
networks:
- monitoring
grafana:
image: grafana/grafana:latest
container_name: grafana
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards
- ./grafana/provisioning/datasources:/etc/grafana/provisioning/datasources
- ./grafana/conf/grafana.ini:/etc/grafana/grafana.ini
environment:
- GF_SECURITY_ADMIN_USER=${GRAFANA_ADMIN_USER}
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_ADMIN_PASSWORD}
- GF_USERS_ALLOW_SIGN_UP=false
- GF_SMTP_ENABLED=true
- GF_SMTP_HOST=${GF_SMTP_HOST}
- GF_SMTP_USER=${GF_SMTP_USER}
- GF_SMTP_PASSWORD=${GF_SMTP_PASSWORD}
- GF_SMTP_FROM_ADDRESS=${GF_SMTP_FROM_ADDRESS}
restart: unless-stopped
ports:
- "3000:3000"
networks:
- monitoring
这是我目前使用的 docker-compose.yml
volumes:
prometheus_data: {}
grafana_data: {}
alertmanager_data: {}
promtail_data: {}
loki_data: {}
mosquitto_data: {}
mosquitto_log: {}
networks:
monitoring:
services:
watchtower:
image: containrrr/watchtower:latest
environment:
- WATCHTOWER_LABEL_ENABLE=true
volumes:
- /var/run/docker.sock:/var/run/docker.sock
labels:
com.centurylinklabs.watchtower.enable: "true"
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- "--path.procfs=/host/proc"
- "--path.rootfs=/rootfs"
- "--path.sysfs=/host/sys"
- "--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)"
ports:
- "9100:9100"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: unless-stopped
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--web.console.libraries=/etc/prometheus/console_libraries"
- "--web.console.templates=/etc/prometheus/consoles"
- "--web.enable-lifecycle"
- "--web.enable-admin-api"
ports:
- "9110:9090"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
cadvisor:
image: gcr.io/cadvisor/cadvisor-arm64:v0.51.0
container_name: cadvisor
privileged: true
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
restart: unless-stopped
devices:
- /dev/kmsg
ports:
- "8080:8080"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
mosquitto:
image: eclipse-mosquitto:latest
container_name: mosquitto
restart: always
ports:
- "1883:1883"
networks:
- monitoring
volumes:
- ./mosquitto/mosquitto.conf:/mosquitto/config/mosquitto.conf
- mosquitto_data:/mosquitto/data
- mosquitto_data:/mosquitto/log
labels:
com.centurylinklabs.watchtower.enable: "true"
loki:
image: grafana/loki:latest
container_name: loki
volumes:
- loki_data:/data
restart: unless-stopped
ports:
- "3100:3100"
command:
- "-config.file=/etc/loki/local-config.yaml"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
promtail:
image: grafana/promtail:latest
container_name: promtail
volumes:
- /var/log:/var/log
- promtail_data:/data
command:
- "-config.file=/etc/promtail/config.yml"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
volumes:
- ./alertmanager/config:/config
- alertmanager_data:/data
- alertmanager_data:/alertmanager
command:
- "--config.file=/config/alertmanager.yml"
restart: always
ports:
- "9093:9093"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
grafana:
image: grafana/grafana:latest
container_name: grafana
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/dashboards:/etc/grafana/provisioning/dashboards
- ./grafana/provisioning/datasources:/etc/grafana/provisioning/datasources
- ./grafana/conf/grafana.ini:/etc/grafana/grafana.ini
environment:
- GF_SECURITY_ADMIN_USER=${GRAFANA_ADMIN_USER}
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_ADMIN_PASSWORD}
- GF_USERS_ALLOW_SIGN_UP=false
- GF_SMTP_ENABLED=true
- GF_SMTP_HOST=${GF_SMTP_HOST}
- GF_SMTP_USER=${GF_SMTP_USER}
- GF_SMTP_PASSWORD=${GF_SMTP_PASSWORD}
- GF_SMTP_FROM_ADDRESS=${GF_SMTP_FROM_ADDRESS}
restart: unless-stopped
ports:
- "3000:3000"
networks:
- monitoring
labels:
com.centurylinklabs.watchtower.enable: "true"
配置.env环境变量
GRAFANA_ADMIN_USER=your-name
GRAFANA_ADMIN_PASSWORD=your-passwd
GRAFANA_DOMAIN=status.microcharon.dev
#Grafana SMTP示例
GF_SMTP_HOST=smtp.outlook.com:587
GF_SMTP_USER=no-reply@microcharon.dev
GF_SMTP_PASSWORD=your-passwd
GF_SMTP_FROM_ADDRESS=no-reply@microcharon.dev
最后用 docker compose up -d 在 docker-compose.yml 当前目录启动就行。由于默认 Grafana 监听 3000 端口,所以访问 3000 端口即可访问到 Grafana WebUI 界面
NGINX 反代
其中一定要注意添加 proxy_set_header 参数,否则登录会 origin not allowed
After update to 8.3.5: 'Origin not allowed' behind proxy - Grafana / Configuration - Grafana Labs Community Forums
location / {
proxy_pass http://127.0.0.1:3000;
proxy_redirect off;
proxy_set_header Host status.microcharon.dev;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
二进制安装配置node exporter
node exporter 部署在服务监控特定的主机上,主要是暴露 metrics 给 Prometheus。建议直接用二进制安装就行
下面是我前些日子写的 1 个简单 script,主要放在我的 ARM 和 amd64 主机上,默认监听 9100 端口,使用前记得添加执行权限。仅作参考,如果有误可以在下方提出我好修改
#!/bin/bash
VER=$(curl -s https://api.github.com/repos/prometheus/node_exporter/releases/latest | grep tag_name | cut -d '"' -f 4 | sed 's/v//')
ARCH=$(uname -m)
TYPE=""
if [ "$ARCH" == "x86_64" ]; then
TYPE="amd64"
elif [ "$ARCH" == "arm5l" ]; then
TYPE="armv5"
elif [ "$ARCH" == "armv6l" ]; then
TYPE="armv6"
elif [ "$ARCH" == "armv7l" ]; then
TYPE="armv7"
elif [ "$ARCH" == "aarch64" ]; then
TYPE="arm64"
fi
wget https://github.com/prometheus/node_exporter/releases/download/v${VER}/node_exporter-${VER}.linux-${TYPE}.tar.gz
tar -zxvf node_exporter*.tar.gz && cp ./node_exporter-${VER}.linux-${TYPE}/node_exporter /usr/local/bin
rm node_exporter*.tar.gz node_exporter*/* && rmdir node_exporter-${VER}.linux-${TYPE}
cat > /etc/systemd/system/node_exporter.service << "EOF"
[Unit]
Description=node_exporter
Documentation=https://github.com/prometheus/node_exporter
[Service]
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9100
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable node_exporter
systemctl start node_exporter
安装好 node_exporter 后访问 9100 端口,在 metrics 路径下可以看到相关常用指标。部分不常用/敏感的指标需要自己另行开启,此处不说
如果担心泄露主机指标信息,可以通过防火墙限制 IP 访问或采用其它高位端口防止,此处不细究
配置prometheus.yml文件
实际上配置很复杂,这里给个参考例子,配置好了可以重启一下 prometheus 或者 curl -X POST http://localhost:9090/-/reload (前提是启用 --web.enable-lifecycle)
注意更换 ip-address 和 instance 的 label
---
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "Node Exporter"
static_configs:
- targets: ["<ip-address>:9100"]
labels:
instance: your-instance-label
- targets: ["<ip-address>:9100"]
labels:
instance: your-instance-label
- job_name: "Cadvisor"
static_configs:
- targets: ["cadvisor:8080"]
labels:
instance: cadvisor
- job_name: "Prometheus"
static_configs:
- targets: ["prometheus:9090"]
labels:
instance: prometheus
添加Prometheus数据源以及import面板
添加 Promethus 数据源如下,一般 http://prometheus:9090 即可,测试一下保存就行
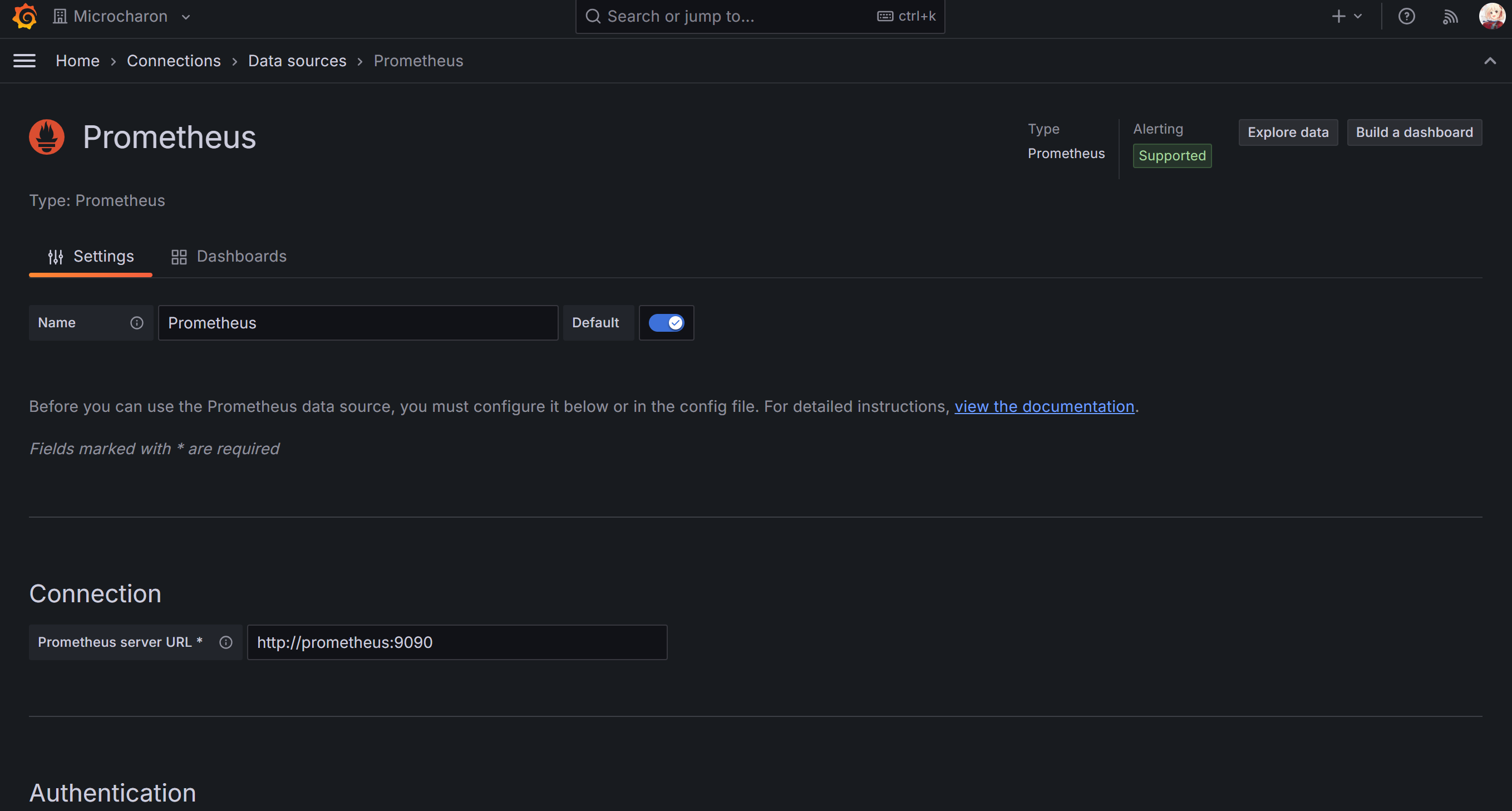
Dashboards | Grafana Labs
一般我们直接用别人的模板就行,推荐以下几个
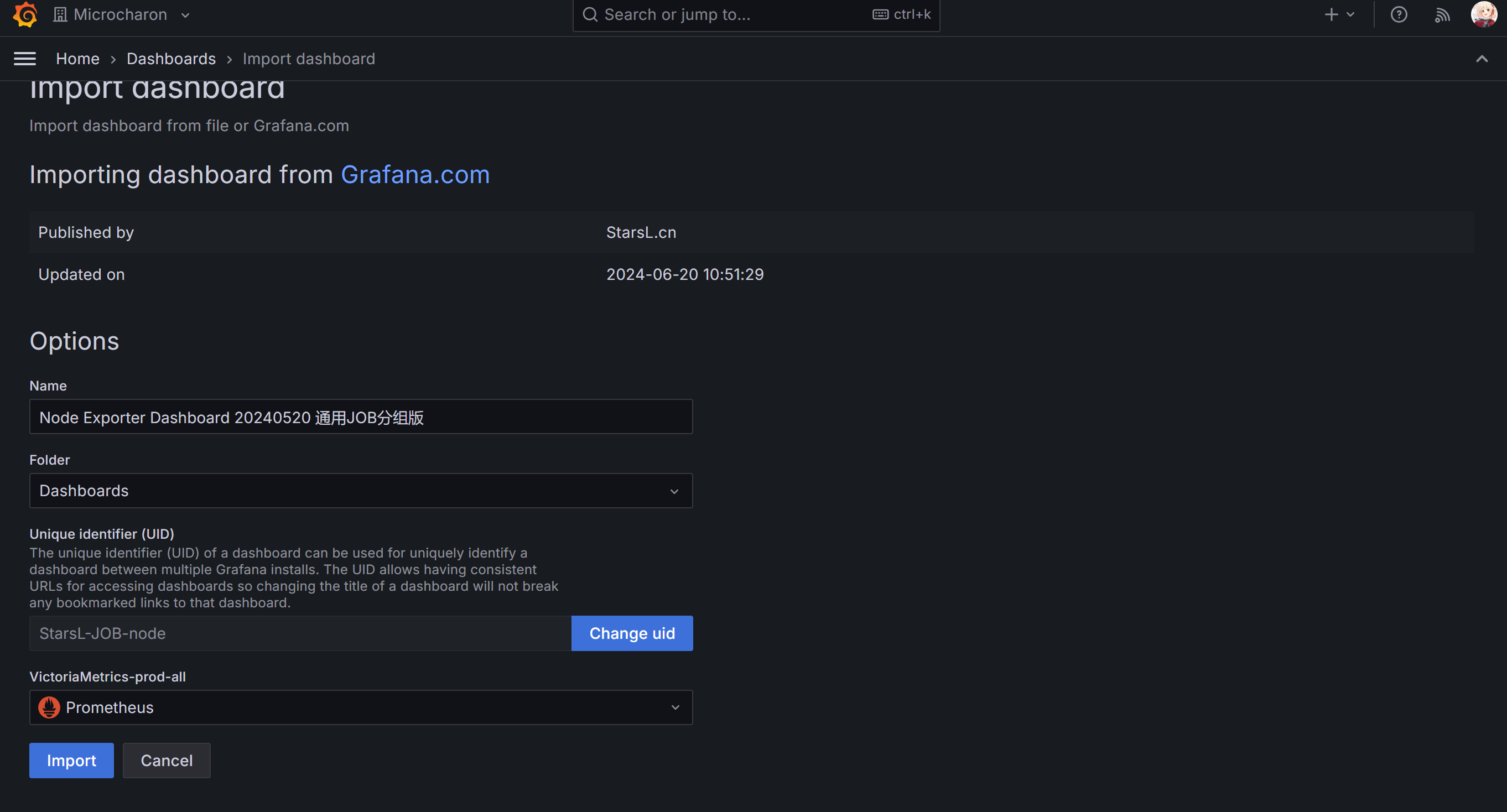
导入模板后添加 Prometheus 数据源即可
开启匿名访问
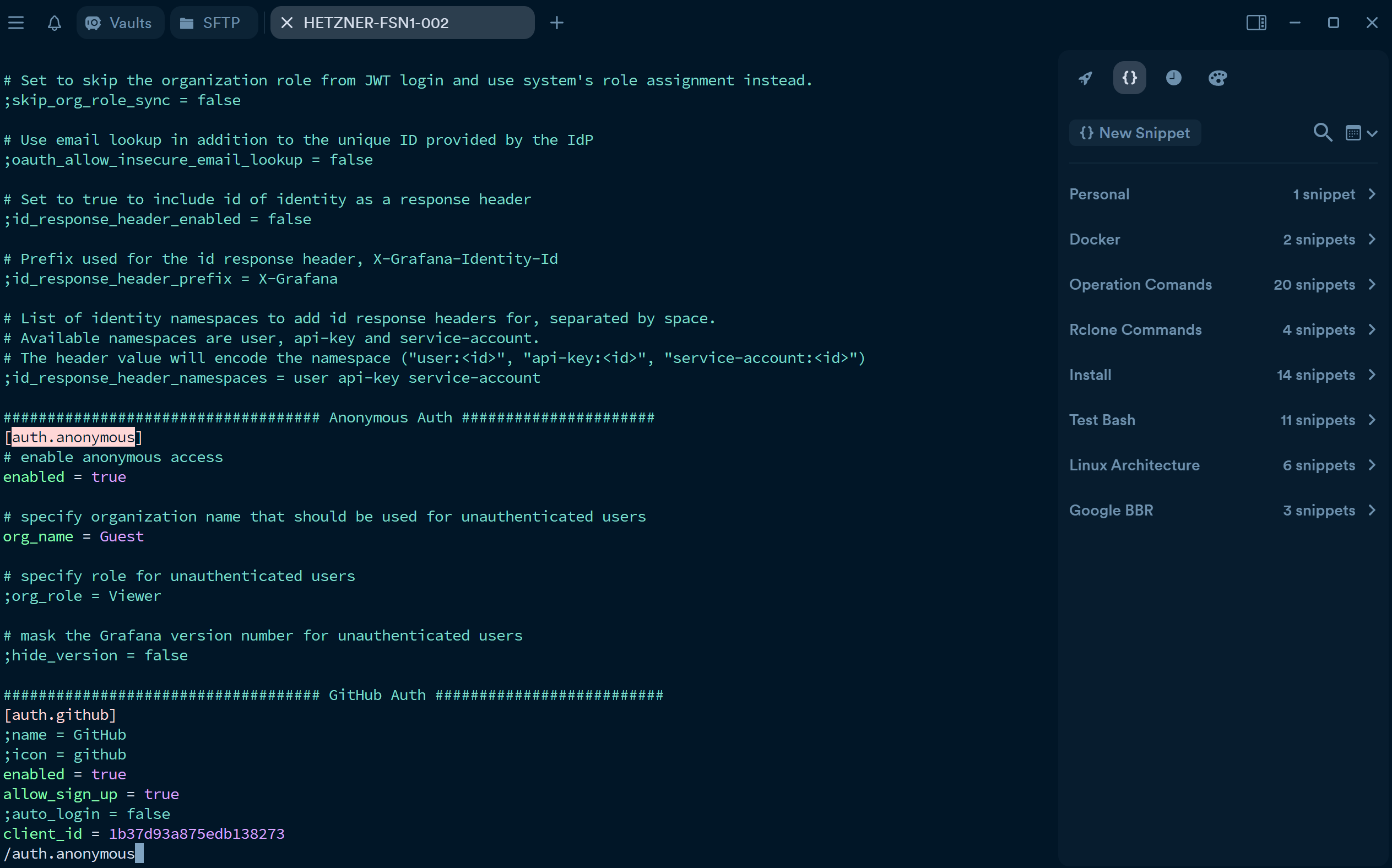
由于我已经提前 ./grafana/conf/grafana.ini:/etc/grafana/grafana.ini 映射出来了,所以可以直接在宿主机上 edit 就行
寻找 auth.anonymous 一行,配置如下。为了防止匿名游客访问我的主要组织,可以先在 web 界面上新建 1 个 organization 如图中的 Guest
然后 restart 一下 Grafana 即可,这样游客访问 Grafana 时就不会访问到你的主要组织
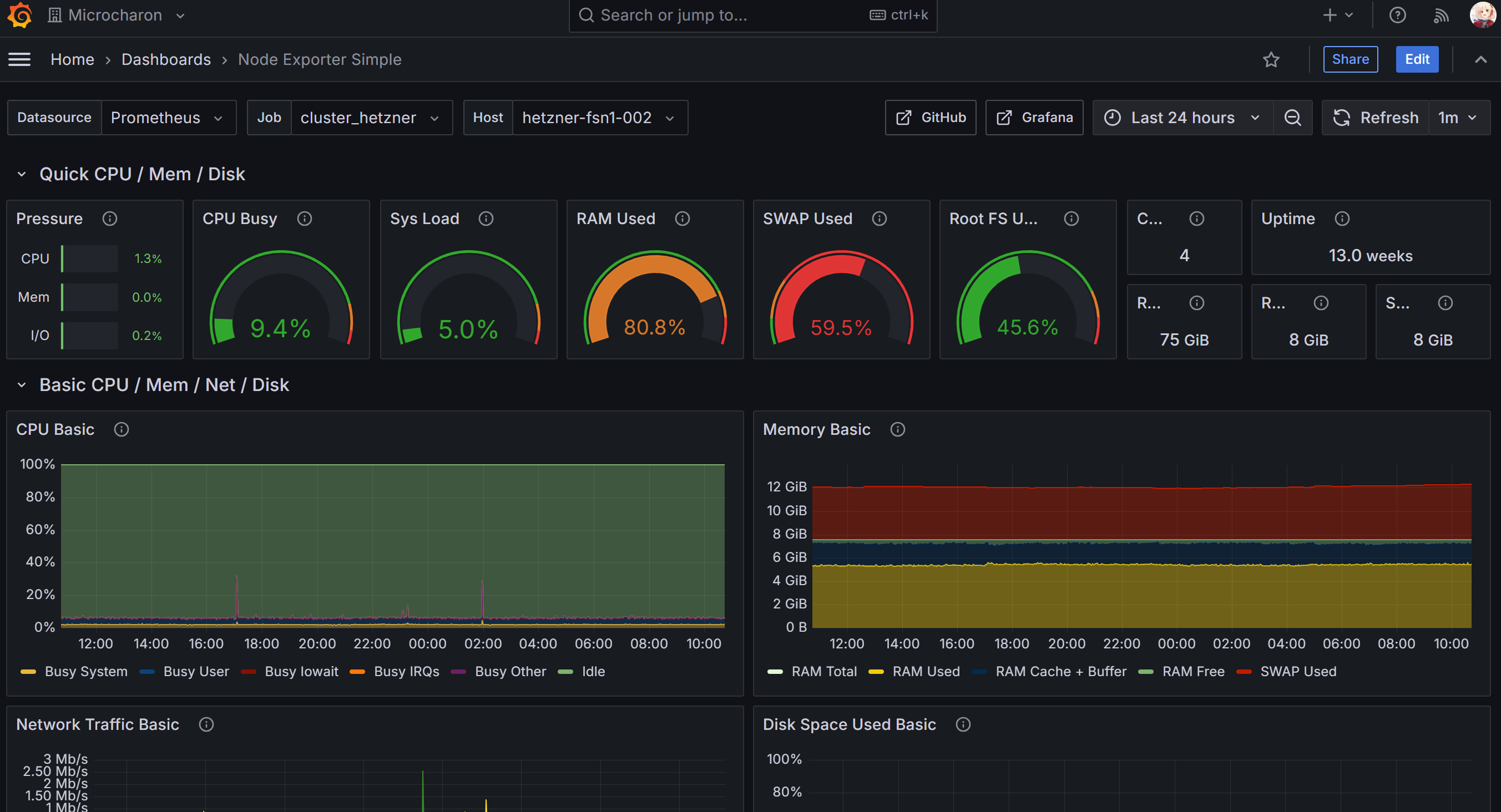
后续可以在 administration 中设置默认 dashboard,这样游客访问时首先看到的就是你设置的默认 dashboard 了
这是我的 Grafana 实例站点:RSS & Atom Reader - Dashboards - Grafana
Alertmanager 规则
如下仅供参考,更多详情请阅览 alertmanager doc 自行更改
通知规则 prometheus-grafana/alertmanager/config/alertmanager.yml
global:
resolve_timeout: 5m
slack_api_url: 'https://hooks.slack.com/services/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'
smtp_from: 'Microcharon Status Dev <no-reply@microcharon.dev>'
smtp_smarthost: 'smtp.outlook.com:587'
smtp_hello: 'status.microcharon.dev'
smtp_auth_username: 'no-reply@microcharon.dev'
smtp_auth_password: 'your-password'
smtp_require_tls: true
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'slack'
routes:
- match:
severity: critical
receiver: 'telegram-and-email'
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
- name: 'slack'
slack_configs:
- send_resolved: true
title: '{{ template "slack.microcharon.title" . }}'
text: '{{ template "slack.microcharon.text" . }}'
actions:
- type: button
text: 'Query :mag:'
url: '{{ (index .Alerts 0).GeneratorURL }}'
- type: button
text: 'Dashboard :chart_with_upwards_trend:'
url: '{{ template "slack.microcharon.dashboard_url" . }}'
- type: button
text: 'Silence :no_bell:'
url: '{{ template "__alert_silence_link" . }}'
- name: 'telegram'
telegram_configs:
- bot_token: 'your-bot-token'
chat_id: your-chat-id
parse_mode: 'HTML'
- name: 'email'
email_configs:
- send_resolved: true
to: 'admin@microcharon.dev'
# from: 'Microcharon Status Dev <no-reply@microcharon.dev>'
# smarthost: 'smtp.outlook.com:587'
# auth_username: 'no-reply@microcharon.dev'
# auth_password: '{password}'
# require_tls: true
- name: 'telegram-and-email'
telegram_configs:
- bot_token: 'your-bot-token'
chat_id: your-chat-id
parse_mode: 'HTML'
email_configs:
- send_resolved: true
to: 'admin@microcharon.dev'
templates:
- '/etc/alertmanager/templates/*.tmpl'
prometheus 报警规则
prometheus-grafana/prometheus/rules/*.yml
rules目录下看放置若干 *.yml 规则,这里只列出我的 node_exporter_alert_rules.yml
groups:
- name: node_exporter_alert_rules
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance of a specific job when CPU usage is above 80% for more than 5 minutes.
- alert: HighCPUUsage
expr: 100 - (avg by (instance, job) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "High CPU usage on {{ $labels.instance }}"
description: "{{ $labels.instance }} ({{ $labels.job }}) has CPU usage above 80% (current value: {{ $value }}%)"

 雷达卡
雷达卡 发表于 2024-12-4 15:04:59
发表于 2024-12-4 15:04:59
 照妖镜
照妖镜